![]()
AIP-210 Dumps Special Discount for limited time Try FOR FREE
AIP-210 Dumps for success in Actual Exam Dec-2025]
NEW QUESTION # 49
Below are three tables: Employees, Departments, and Directors.
Employee_Table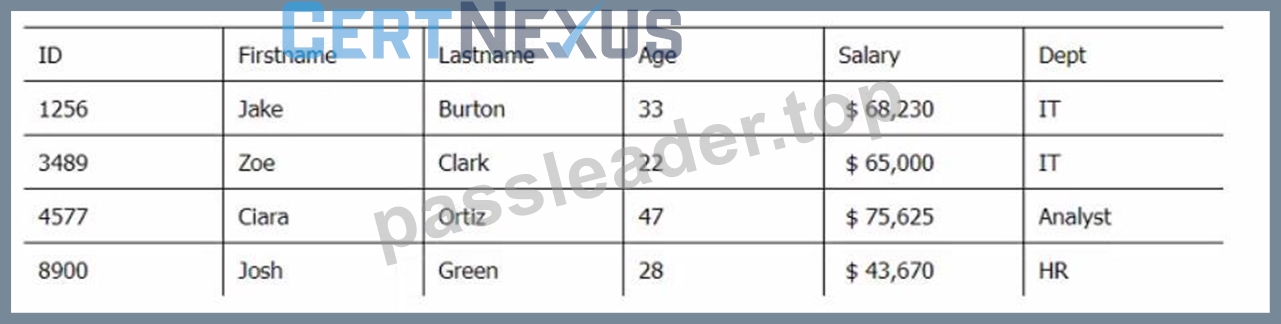
Department_Table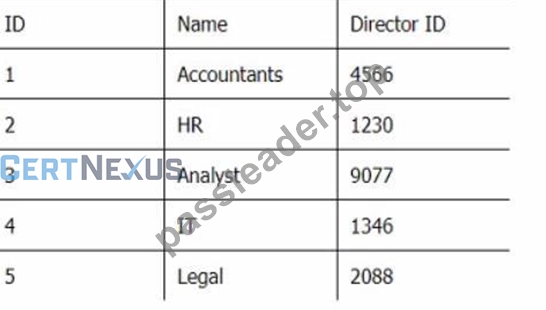
Director_Table
ID
Firstname
Lastname
Age
Salary
DeptJD
4566
Joey
Morin
62
$ 122,000
1
1230
Sam
Clarck
43
$ 95,670
2
9077
Lola
Russell
54
$ 165,700
3
1346
Lily
Cotton
46
$ 156,000
4
2088
Beckett
Good
52
$ 165,000
5
Which SQL query provides the Directors' Firstname, Lastname, the name of their departments, and the average employee's salary?
- A. SELECT m.Firstname, m.Lastname, d.Name, AVG(e.Salary) as Dept_avg_Salary FROM Employee_Table as e RIGHT JOIN Department_Table as d on e.Dept = d.Name INNER JOIN Directorjable as m on d.ID = m.DeptID GROUP BY m.Firstname, m.Lastname, d.Name
- B. SELECT m.Firstname, m.Lastname, d.Name, AVG(e.Salary) as Dept_avg_Salary FROM Employee_Table as e RIGHT JOIN Departmentjable as d on e.Dept = d.Name INNER JOIN Directorjable as m on d.ID = m.DeptJD GROUP BY d.Name
- C. SELECT m.Firstname, m.Lastname, d.Name, AVG(e.Saiary) as Dept_avg_Saiary FROM Employee_Table as e LEFT JOIN Department_Table as d on e.Dept = d.Name LEFT JOIN Directorjable as m on d.ID = m.DeptJD GROUP BY m.Firstname, m.Lastname, d.Name
- D. SELECT m.Firstname, m.Lastname, d.Name, AVG(e.Salary) as Dept_avg_Salary FROM Employee_Table as e RIGHT JOIN Department_Table as d on e.Dept = d.Name INNER JOIN Directorjable as m on d.ID = m.DeptJD GROUP BY e.Salary
Answer: A
Explanation:
Explanation
This SQL query provides the Directors' Firstname, Lastname, the name of their departments, and the average employee's salary by joining the three tables using the appropriate join types and conditions. The RIGHT JOIN between Employee_Table and Department_Table ensures that all departments are included in the result, even if they have no employees. The INNER JOIN between Department_Table and Directorjable ensures that only departments with directors are included in the result. The GROUP BY clause groups the result by the directors' names and departments' names, and calculates the average salary for each group using the AVG function. References: SQL Joins - W3Schools, SQL GROUP BY Statement - W3Schools
NEW QUESTION # 50
You are building a prediction model to develop a tool that can diagnose a particular disease so that individuals with the disease can receive treatment. The treatment is cheap and has no side effects. Patients with the disease who don't receive treatment have a high risk of mortality.
It is of primary importance that your diagnostic tool has which of the following?
- A. Low false positive rate
- B. High positive predictive value
- C. Low false negative rate
- D. High negative predictive value
Answer: C
Explanation:
Explanation
A false negative is an error where a positive case (belonging to the target class) is incorrectly predicted as negative (not belonging to the target class). A false negative rate is the ratio of false negatives to all actual positive cases. A low false negative rate means that most of the positive cases are correctly identified by the classifier.
For a diagnostic tool that can diagnose a particular disease so that individuals with the disease can receive treatment, it is of primary importance that it has a low false negative rate. This is because false negatives can have serious consequences for patients who have the disease but do not receive treatment, such as increased risk of mortality or complications. A low false negative rate can ensure that most patients who have the disease are diagnosed correctly and receive timely treatment.
NEW QUESTION # 51
In general, models that perform their tasks:
- A. Less accurately are neither more nor less robust against adversarial attacks.
- B. More accurately are neither more nor less robust against adversarial attacks.
- C. More accurately are less robust against adversarial attacks.
- D. Less accurately are less robust against adversarial attacks.
Answer: C
Explanation:
Explanation
Adversarial attacks are malicious attempts to fool or manipulate machine learning models by adding small perturbations to the input data that are imperceptible to humans but can cause significant changes in the model output. In general, models that perform their tasks more accurately are less robust against adversarial attacks, because they tend to have higher confidence in their predictions and are more sensitive to small changes in the input data. References: [Adversarial machine learning - Wikipedia], [Why Are Machine Learning Models Susceptible to Adversarial Attacks? | by Anirudh Jain | Towards Data Science]
NEW QUESTION # 52
Which type of regression represents the following formula: y = c + b*x, where y = estimated dependent variable score, c = constant, b = regression coefficient, and x = score on the independent variable?
- A. Lasso regression
- B. Linear regression
- C. Ridge regression
- D. Polynomial regression
Answer: B
NEW QUESTION # 53
A dataset can contain a range of values that depict a certain characteristic, such as grades on tests in a class during the semester. A specific student has so far received the following grades: 76,81, 78, 87, 75, and 72.
There is one final test in the semester. What minimum grade would the student need to achieve on the last test to get an 80% average?
- A. 0
- B. 1
- C. 2
- D. 3
Answer: B
Explanation:
Explanation
To calculate the minimum grade needed to achieve an 80% average, we can use the following formula:
minimum grade = (target average * number of tests - sum of grades) / (number of tests - 1) Plugging in the given values, we get:
minimum grade = (80 * 7 - (76 + 81 + 78 + 87 + 75 + 72)) / (7 - 6)
minimum grade = (560 - 469) / 1
minimum grade = 91
Therefore, the student needs to score at least 91 on the last test to get an 80% average.
NEW QUESTION # 54
Which of the following is a common negative side effect of not using regularization?
- A. Slow convergence time
- B. Higher compute resources
- C. Overfitting
- D. Low test accuracy
Answer: C
Explanation:
Explanation
Overfitting is a common negative side effect of not using regularization. Regularization is a technique that reduces the complexity of a model by adding a penalty term to the loss function, which prevents the model from learning too many parameters that may fit the noise in the training data. Overfitting occurs when the model performs well on the training data but poorly on the test data or new data, because it has memorized the training data and cannot generalize well. References: Regularization (mathematics) - Wikipedia, Overfitting in Machine Learning: What It Is and How to Prevent It
NEW QUESTION # 55
In which of the following scenarios is lasso regression preferable over ridge regression?
- A. The sample size is much larger than the number of features.
- B. The number of features is much larger than the sample size.
- C. There is high collinearity among some of the features associated with the dependent variable.
- D. There are many features with no association with the dependent variable.
Answer: D
Explanation:
Explanation
Lasso regression is a type of linear regression that adds a regularization term to the loss function to reduce overfitting and improve generalization. Lasso regression uses an L1 norm as the regularization term, which is the sum of the absolute values of the coefficients. Lasso regression can shrink some of the coefficients to zero, which effectively eliminates some of the features from the model. Lasso regression is preferable over ridge regression when there are many features with no association with the dependent variable, as it can perform feature selection and reduce the complexity and noise of the model.
NEW QUESTION # 56
Which of the following models are text vectorization methods? (Select two.)
- A. Lemmatization
- B. PCA
- C. Tokenization
- D. TF-IDF
- E. Skip-gram
- F. t-SNE
Answer: D,E
Explanation:
Explanation
Skip-gram and TF-IDF are both text vectorization methods that convert text into numerical feature vectors.
Skip-gram is a prediction-based word embedding method that learns vector representations of words from their contexts in a large corpus of text. TF-IDF is a frequency-based word weighting method that assigns scores to words based on their importance in a document and in a corpus of documents. References: Text Vectorization and Word Embedding | Guide to Master NLP (Part 5), What Is Text Vectorization? Everything You Need to Know - deepset
NEW QUESTION # 57
Which of the following describes a benefit of machine learning for solving business problems?
- A. Increasing the speed of analysis
- B. Increasing the quantity of original data
- C. Improving the quality of original data
- D. Improving the constraint of the problem
Answer: A
Explanation:
Explanation
Increasing the speed of analysis is a benefit of machine learning for solving business problems. Machine learning is a branch of artificial intelligence that involves creating systems that can learn from data and make predictions or decisions. Machine learning can help increase the speed of analysis by automating and optimizing various tasks, such as data processing, feature extraction, model training, model evaluation, or model deployment. Machine learning can also help handle large and complex data sets that may be difficult or impractical to analyze manually or with traditional methods.
NEW QUESTION # 58
Which of the following pieces of AI technology provides the ability to create fake videos?
- A. Long short-term memory (LSTM) networks
- B. Support-vector machines (SVM)
- C. Recurrent neural networks (RNN)
- D. Generative adversarial networks (GAN)
Answer: D
Explanation:
Generative adversarial networks (GAN) are a type of AI technology that can create fake videos, images, audio, or text that are realistic and indistinguishable from real ones. GAN consist of two neural networks: a generator and a discriminator. The generator tries to produce fake samples from random noise, while the discriminator tries to distinguish between real and fake samples. The two networks compete against each other in a game-like scenario, where the generator tries to fool the discriminator and the discriminator tries to catch the generator. Through this process, both networks improve their abilities until they reach an equilibrium where the generator can produce convincing fakes.
NEW QUESTION # 59
Which three security measures could be applied in different ML workflow stages to defend them against malicious activities? (Select three.)
- A. Monitor model degradation.
- B. Launch ML Instances In a virtual private cloud (VPC).
- C. Use data encryption.
- D. Use max privilege to control access to ML artifacts.
- E. Disable logging for model access.
- F. Use Secrets Manager to protect credentials.
Answer: B,C,F
Explanation:
Explanation
Security measures can be applied in different ML workflow stages to defend them against malicious activities, such as data theft, model tampering, or adversarial attacks. Some of the security measures are:
Launch ML Instances In a virtual private cloud (VPC): A VPC is a logically isolated section of a cloud provider's network that allows users to launch and control their own resources. By launching ML instances in a VPC, users can enhance the security and privacy of their data and models, as well as restrict the access and traffic to and from the instances.
Use data encryption: Data encryption is the process of transforming data into an unreadable format using a secret key or algorithm. Data encryption can protect the confidentiality, integrity, and availability of data at rest (stored in databases or files) or in transit (transferred over networks). Data encryption can prevent unauthorized access, modification, or leakage of sensitive data.
Use Secrets Manager to protect credentials: Secrets Manager is a service that helps users securely store, manage, and retrieve secrets, such as passwords, API keys, tokens, or certificates. Secrets Manager can help users protect their credentials from unauthorized access or exposure, as well as rotate them automatically to comply with security policies.
NEW QUESTION # 60
Which two of the following statements about the beta value in an A/B test are accurate? (Select two.)
- A. The statistical power of a test is the inverse of the Beta value, or 1 - Beta.
- B. The Beta value is the rate of type I errors for the test.
- C. The Beta value is the rate of type II errors for the test.
- D. The Beta in an Alpha/Beta test represents one of the two variants of the A/B test.
Answer: C
Explanation:
Explanation
The Beta value in an A/B test is the probability of making a type II error, which is failing to reject the null hypothesis when it is false. The statistical power of a test is the probability of correctly rejecting the null hypothesis when it is false, which is equal to 1 - Beta. References: Formulas for Bayesian A/B Testing - Evan Miller, The Practical Guide To AB testing statistics | Convertize
NEW QUESTION # 61
Which of the following is the primary purpose of hyperparameter optimization?
- A. Increases recall over precision
- B. Makes models easier to explain to business stakeholders
- C. Controls the learning process of a given algorithm
- D. Improves model interpretability
Answer: C
Explanation:
Hyperparameter optimization is the process of finding the optimal values for hyperparameters that control the learning process of a given algorithm. Hyperparameters are parameters that are not learned by the algorithm but are set by the user before training. Hyperparameters can affect the performance and behavior of the algorithm, such as its speed, accuracy, complexity, or generalization. Hyperparameter optimization can help improve the efficiency and effectiveness of the algorithm by tuning its hyperparameters to achieve the best results.
NEW QUESTION # 62
When should the model be retrained in the ML pipeline?
- A. A new monitoring component is added.
- B. More data become available for the training phase.
- C. Some outliers are detected in live data.
- D. Concept drift is detected in the pipeline.
Answer: D
Explanation:
Explanation
When concept drift is detected in the pipeline, it means that the model performance has degraded over time due to changes in the underlying data generating process. This requires retraining the model with new data that reflects the current situation and updating the model parameters accordingly. References: Use pipeline parameters to retrain models in the designer - Azure Machine Learning | Microsoft Learn, Retraining Model During Deployment: Continuous Training and Continuous Testing
NEW QUESTION # 63
You have a dataset with many features that you are using to classify a dependent variable. Because the sample size is small, you are worried about overfitting. Which algorithm is ideal to prevent overfitting?
- A. XGBoost
- B. Random forest
- C. Decision tree
- D. Logistic regression
Answer: B
NEW QUESTION # 64
An organization sells house security cameras and has asked their data scientists to implement a model to detect human feces, as distinguished from animals, so they can alert th customers only when a human gets close to their house.
Which of the following algorithms is an appropriate option with a correct reason?
- A. Neural network model, because this is a classification problem with a large number of features.
- B. k-means, because this is a clustering problem with a small number of features.
- C. A decision tree algorithm, because the problem is a classification problem with a small number of features.
- D. Logistic regression, because this is a classification problem and our data is linearly separable.
Answer: A
Explanation:
Neural network models are suitable for classification problems with a large number of features, because they can learn complex and non-linear patterns from high-dimensional data. They can also handle image data, which is likely to be the input for the human face detection problem. Neural networks can also be trained using transfer learning, which can leverage pre-trained models on similar tasks and improve the accuracy and efficiency of the model. References: [Neural network - Wikipedia], [Transfer Learning - Machine Learning's Next Frontier]
NEW QUESTION # 65
In general, models that perform their tasks:
- A. Less accurately are neither more nor less robust against adversarial attacks.
- B. More accurately are neither more nor less robust against adversarial attacks.
- C. More accurately are less robust against adversarial attacks.
- D. Less accurately are less robust against adversarial attacks.
Answer: C
Explanation:
Explanation
Adversarial attacks are malicious attempts to fool or manipulate machine learning models by adding small perturbations to the input data that are imperceptible to humans but can cause significant changes in the model output. In general, models that perform their tasks more accurately are less robust against adversarial attacks, because they tend to have higher confidence in their predictions and are more sensitive to small changes in the input data. References: [Adversarial machine learning - Wikipedia], [Why Are Machine Learning Models Susceptible to Adversarial Attacks? | by Anirudh Jain | Towards Data Science]
NEW QUESTION # 66
Which of the following principles supports building an ML system with a Privacy by Design methodology?
- A. Understanding, documenting, and displaying data lineage.
- B. Avoiding mechanisms to explain and justify automated decisions.
- C. Collecting and processing the largest amount of data possible.
- D. Utilizing quasi-identifiers and non-unique identifiers, alone or in combination.
Answer: A
Explanation:
Data lineage is the process of tracking the origin, transformation, and usage of data throughout its lifecycle. It helps to ensure data quality, integrity, and provenance. Data lineage also supports the Privacy by Design methodology, which is a framework that aims to embed privacy principles into the design and operation of systems, processes, and products that involve personal data. By understanding, documenting, and displaying data lineage, an ML system can demonstrate how it collects, processes, stores, and deletes personal data in a transparent and accountable manner3 .
NEW QUESTION # 67
Which of the following sentences is TRUE about the definition of cloud models for machine learning pipelines?
- A. Software as a Service (SaaS) can provide AI practitioner data science services such as Jupyter notebooks.
- B. Platform as a Service (PaaS) can provide some services within an application such as payment applications to create efficient results.
- C. Infrastructure as a Service (IaaS) can provide CPU, memory, disk, network and GPU.
- D. Data as a Service (DaaS) can host the databases providing backups, clustering, and high availability.
Answer: A
Explanation:
Explanation
Cloud models are service models that provide different levels of abstraction and control over computing resources in a cloud environment. Some of the common cloud models for machine learning pipelines are:
Software as a Service (SaaS): SaaS provides ready-to-use applications that run on the cloud provider's infrastructure and are accessible through a web browser or an API. SaaS can provide AI practitioner data science services such as Jupyter notebooks, which are web-based interactive environments that allow users to create and share documents that contain code, text, visualizations, and more.
Platform as a Service (PaaS): PaaS provides a platform that allows users to develop, run, and manage applications without worrying about the underlying infrastructure. PaaS can provide some services within an application such as payment applications to create efficient results.
Infrastructure as a Service (IaaS): IaaS provides access to fundamental computing resources such as servers, storage, networks, and operating systems. IaaS can provide CPU, memory, disk, network and GPU resources that can be used to run machine learning models and applications.
Data as a Service (DaaS): DaaS provides access to data sources that can be consumed by applications or users on demand. DaaS can host the databases providing backups, clustering, and high availability.
NEW QUESTION # 68
Which of the following is the definition of accuracy?
- A. (True Positives + False Positives) / Total Predictions
- B. (True Positives + True Negatives) / Total Predictions
- C. True Positives / (True Positives + False Negatives)
- D. True Positives / (True Positives + False Positives)
Answer: B
Explanation:
Accuracy is a measure of how well a classifier can correctly predict the class of an instance. Accuracy is calculated by dividing the number of correct predictions (true positives and true negatives) by the total number of predictions. True positives are instances that are correctly predicted as positive (belonging to the target class). True negatives are instances that are correctly predicted as negative (not belonging to the target class).
NEW QUESTION # 69
A data scientist is tasked to extract business intelligence from primary data captured from the public. Which of the following is the most important aspect that the scientist cannot forget to include?
- A. Data privacy
- B. Cybersecurity
- C. Cyberprotection
- D. Data security
Answer: A
Explanation:
Explanation
Data privacy is the right of individuals to control how their personal data is collected, used, shared, and protected. It also involves complying with relevant laws and regulations that govern the handling of personal data. Data privacy is especially important when extracting business intelligence from primary data captured from the public, as it may contain sensitive or confidential information that could harm the individuals if misused or breached .
NEW QUESTION # 70
Which of the following options is a correct approach for scheduling model retraining in a weather prediction application?
- A. Once a month
- B. When the input volume changes
- C. As new resources become available
- D. When the input format changes
Answer: D
Explanation:
The input format is the way that the data is structured, organized, and presented to the model. For example, the input format could be a CSV file, an image file, or a JSON object. The input format can affect how the model interprets and processes the data, and therefore how it makes predictions. When the input format changes, it may require retraining the model to adapt to the new format and ensure its accuracy and reliability.
For example, if the weather prediction application switches from using numerical values to categorical values for some features, such as wind direction or cloud cover, it may need to retrain the model to handle these changes .
NEW QUESTION # 71
An AI practitioner incorporates risk considerations into a deployment plan and decides to log and store historical predictions for potential, future access requests.
Which ethical principle is this an example of?
- A. Privacy
- B. Safety
- C. Transparency
- D. Fairness
Answer: C
Explanation:
Explanation
Transparency is an ethical principle that describes the degree to which an AI system can provide clear and understandable information about its inputs, outputs, processes, and decisions. Transparency can help increase trust and confidence among users and stakeholders, as well as enable accountability and responsibility for the system's actions and outcomes. Logging and storing historical predictions for potential, future access requests is an example of transparency, as it can help provide evidence and explanation for the system's recommendations, as well as facilitate auditing and feedback.
NEW QUESTION # 72
Which of the following is a privacy-focused law that an AI practitioner should adhere to while designing and adapting an AI system that utilizes personal data?
- A. ISO/IEC 27001
- B. General Data Protection Regulation (GDPR)
- C. Sarbanes Oxley (SOX)
- D. PCIDSS
Answer: B
Explanation:
Explanation
The General Data Protection Regulation (GDPR) is a privacy-focused law that an AI practitioner should adhere to while designing and adapting an AI system that utilizes personal data. The GDPR applies to any organization that processes personal data of individuals in the European Union (EU), regardless of where the organization is located. The GDPR grants individuals rights over their personal data, such as the right to access, rectify, erase, restrict, or object to its processing. The GDPR also imposes obligations on organizations that process personal data, such as the duty to obtain consent, conduct data protection impact assessments, implement data protection by design and by default, and ensure accountability and transparency. The GDPR also addresses some specific issues related to AI, such as automated decision-making, profiling, and data portability.
NEW QUESTION # 73
You are developing a prediction model. Your team indicates they need an algorithm that is fast and requires low memory and low processing power. Assuming the following algorithms have similar accuracy on your data, which is most likely to be an ideal choice for the job?
- A. Deep learning neural network
- B. Support-vector machine
- C. Random forest
- D. Ridge regression
Answer: D
Explanation:
Explanation
Ridge regression is a type of linear regression that adds a regularization term to the loss function to reduce overfitting and improve generalization. Ridge regression is fast and requires low memory and low processing power, as it only involves solving a system of linear equations. Ridge regression can also handle multicollinearity (high correlation among predictors) by shrinking the coefficients of correlated predictors.
NEW QUESTION # 74
......
CertNexus AIP-210 Exam Syllabus Topics:
| Topic | Details |
|---|---|
| Topic 1 |
|
| Topic 2 |
|
| Topic 3 |
|
Accurate AIP-210 Answers 365 Days Free Updates: https://examcertify.passleader.top/CertNexus/AIP-210-exam-braindumps.html